Query Routing for LLM Applications
February 3, 2026Introduction
Many LLM-based applications are not single-purpose. A chatbot might need to fetch live stock prices for one query and look up a weather forecast for another. The job of figuring out which handler to invoke for a given user message is called query routing, and getting it wrong means either failing the user or sending the query to a handler that will return nonsense.
The obvious solution is to let a general-purpose LLM handle routing — describe the available capabilities and ask it which one applies. No custom code required. The problem is latency. A cold LLM call easily takes 30–60 seconds end-to-end, and more complex agentic workflows that write SQL against internal tables can take 5+ minutes. In many situations, this blocks the user from getting the data they need quickly.
The naive fallback — a chain of if/elif blocks checking for
keywords — breaks almost immediately in production. Users misspell words, rephrase intent in
unexpected ways, and ask semantically equivalent questions using completely different vocabulary.
In this article we build a small routing library that handles these cases using two complementary
techniques: Jaccard similarity over character n-grams, and sentence embedding cosine similarity.
We then compose them so that the more powerful (but heavier) embedding approach is preferred when
available, with the lightweight Jaccard approach as a reliable fallback. The tradeoff is upfront
implementation work. Jaccard routing itself takes < 1 ms; the full round-trip —
routing plus calling the right downstream API and returning a response — should come back within
a couple hundred milliseconds. You can push this even lower by bundling the route signal and input data into
a single message rather than two sequential calls, keeping the full response time under a few hundred milliseconds.
This is much faster than more general-purpose LLM/RAG systems as described above.
The Interface
We start by defining the contract. Route is an enum of the available destinations.
RouterPort is an abstract base class that carries the shared route description
dictionary and declares a single method, find_route, that all implementations must
satisfy. The dictionary maps natural-language descriptions of each intent to its Route
value; these descriptions are what the router will compare incoming queries against.
class Route(Enum):
STOCK_PRICES = "STOCK_PRICES"
WEATHER = "WEATHER"
class RouterPort(ABC):
ROUTER_OPTIONS: dict[str, Route] = {
"stocks": Route.STOCK_PRICES,
"find me stock prices": Route.STOCK_PRICES,
"stock market": Route.STOCK_PRICES,
...,
"weather": Route.WEATHER,
"temperature": Route.WEATHER,
"what is the weather?": Route.WEATHER,
"what is the temperature?": Route.WEATHER,
...
}
@abstractmethod
def find_route(self, query: str) -> Route:
pass
The descriptions in ROUTER_OPTIONS serve as a training set of sorts — they
encode the vocabulary and phrasing the router should recognize for each intent. Adding a new route
is simply a matter of adding a new Route value and populating the dictionary with
representative phrases.
Jaccard Similarity with Character N-grams
Jaccard similarity between two sets and is defined as
and ranges from 0 (disjoint) to 1 (identical). If we tokenize queries into words and compare word sets, we get a reasonable similarity measure — but it is brittle. A user who types “wheather” instead of “weather” produces a word token that shares no overlap with any route description.
Character n-grams solve this. We slide a window of length
across the full string — spaces included —
producing overlapping character substrings. A single typo corrupts at most
consecutive n-grams while leaving the rest intact.
The query “wheather” with produces
{"whea", "heat", "eath", "athe", "ther"}, which overlaps substantially with
the n-grams of “weather”. Including spaces means n-grams also capture context
at word boundaries: the substring "ck p" (a consonant cluster, a space, and the
next word's first letter) is shared between two strings that differ only in vowels around
that cluster. It also handles a typo class that per-word n-grams cannot: space insertions
and deletions. A query like “stockprices” or “sto ck” splits into
the wrong word tokens entirely, but its full-string trigrams still overlap substantially
with “stock prices.” We use a mix of n-gram sizes (4, 5, and 6) unioned
together, along with the word-level tokens, so the scorer benefits from both word-level
and character-level signal.
class JaccardRouter:
@staticmethod
def jaccard_similarity(set1: set[str], set2: set[str]) -> float:
intersection = set1 & set2
union = set1 | set2
if not union:
return 0.0
return len(intersection) / len(union)
@staticmethod
def tokenize_string(s: str) -> set[str]:
return set(s.split())
@staticmethod
def compute_ngrams(s: str, n: int) -> set[str]:
ngrams = set()
if len(s) < n:
return ngrams
for i in range(len(s) - (n - 1)):
ngram = s[i : i + n]
ngrams.add(ngram)
return ngrams
@staticmethod
def compute_all_ngrams(s: str, n: list[int]) -> set[str]:
result = JaccardRouter.tokenize_string(s)
for k in n:
result |= JaccardRouter.compute_ngrams(s, k)
return result
@staticmethod
def get_best_candidate(request: str, candidate_routes: set[str], n: list[int]
) -> Optional[Tuple[str, float]]:
max_score = 0.0
candidate, candidate_score = "", 0.0
for desc in candidate_routes:
jac = JaccardRouter.jaccard_similarity(
JaccardRouter.compute_all_ngrams(request, n),
JaccardRouter.compute_all_ngrams(desc, n)
)
if jac > max_score:
max_score = jac
candidate, candidate_score = desc, jac
if candidate == "":
return None
return candidate, candidate_score
get_best_candidate scores the incoming query against every description in
ROUTER_OPTIONS and returns the best match. The adapter below wires this into the
port interface, resolving the winning description back to its Route value.
class JaccardRouterAdapter(RouterPort):
def find_route(self, query: str) -> Route:
candidate_route_strings = set(RouterPort.ROUTER_OPTIONS.keys())
best_candidate, _ = JaccardRouter.get_best_candidate(
query, candidate_route_strings, n=[4, 5, 6]
)
route = RouterPort.ROUTER_OPTIONS[best_candidate]
if route is None:
raise MissingRouteException()
return route
To see why character n-grams matter, consider the query “find me stck prces” compared against two route descriptions: “find me stock prices” and “find me weather.”
Word-level Jaccard scores the query as {find, me, stck, prces}. The intersection with “find me weather” is {find, me}, giving . The intersection with “find me stock prices” is also {find, me}, giving . Word Jaccard picks the wrong route.
Full-string trigrams recover the correct answer. The 16 trigrams of “find me stck
prces” include the shared prefix substrings fin ind "nd " "d m" " me" "me " "e s"
" st", plus cross-word substrings "ck " "k p" " pr" that appear in both
“stck prces” and “stock prices” because the consonant cluster and the
following space are identical despite the different vowels, plus the shared tail ces.
Together with the word tokens, 14 of the 28 union tokens are shared with
“find me stock prices” —
. Only 8 are shared with
“find me weather”, which diverges after "e s" —
.
The trigram scorer picks the right route by a clear margin.
Embedding-Based Routing
Jaccard over n-grams handles typos well but can struggle with paraphrases that share little surface-level text. “What’s the temperature outside?” and “Is it going to rain?” are semantically related to weather but share almost no n-grams with the description “weather forecast.” Sentence embeddings address this by mapping strings into a high-dimensional vector space where semantically similar strings land near each other regardless of surface form.
To compare two vectors we use cosine similarity rather than Euclidean distance. Distance becomes unreliable in high-dimensional spaces — as dimensionality grows, distances between points concentrate and lose discriminative power (the curse of dimensionality). Cosine similarity sidesteps this by measuring the angle between vectors instead of how far apart they are, which stays meaningful regardless of dimension.
The diagram below shows two vectors in 2D space and the angle between them. The plot shows how behaves over : an angle of zero gives a similarity of 1 (identical direction), and the score decreases toward 0 as the vectors diverge. In practice, embedding models are trained specifically to produce this geometry — for example via contrastive learning, where the model is given pairs of similar and dissimilar strings and learns to place them close together or far apart in the vector space accordingly.
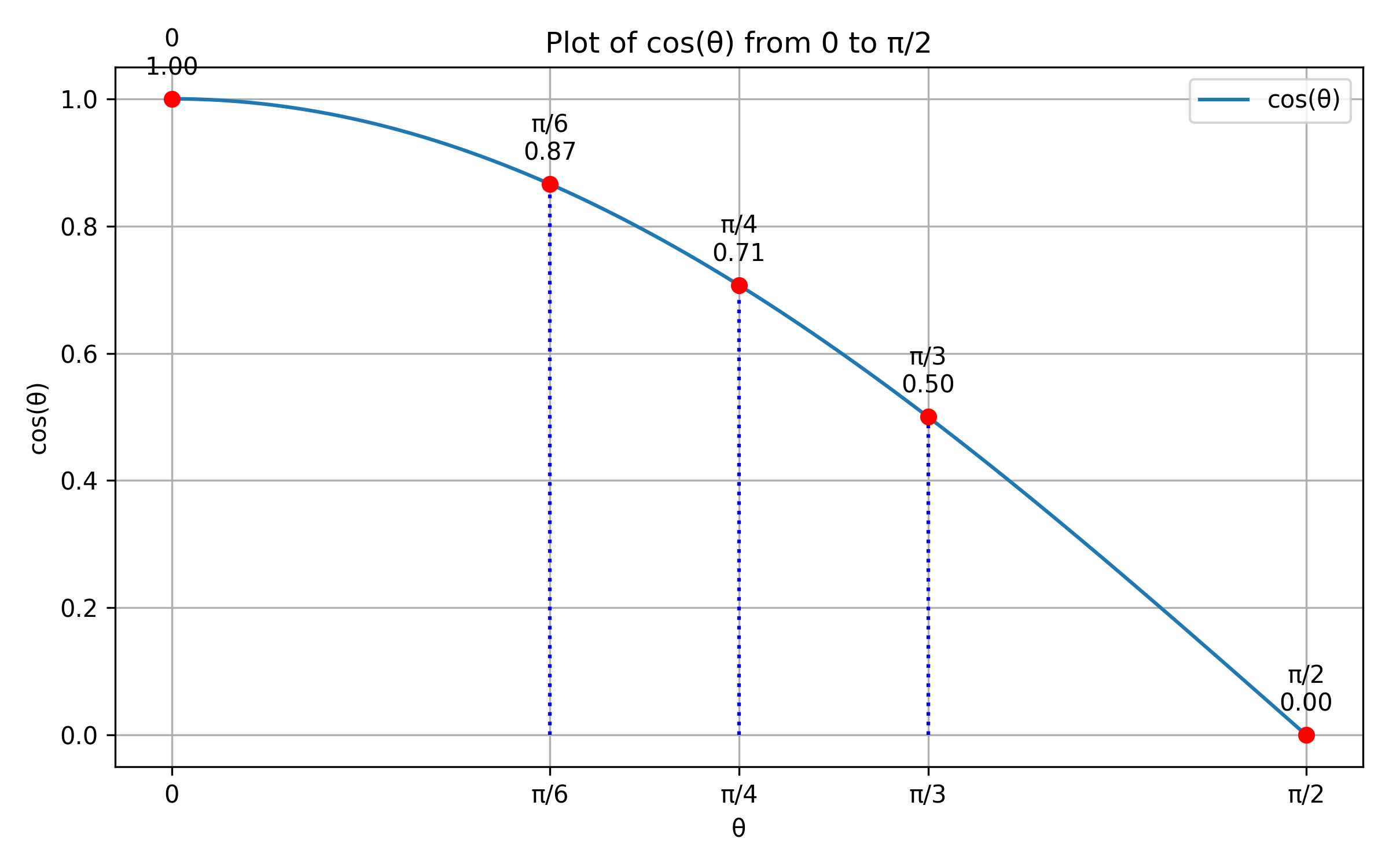
At construction time, we encode every route description once and cache the resulting vectors. At query time, we encode the incoming query, compute cosine similarity against each cached vector, and return the route corresponding to the highest score.
class EmbeddingRouterAdapter(RouterPort):
@staticmethod
def similarity(a: np.ndarray, b: np.ndarray) -> float:
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
def __init__(self) -> None:
sentence_keys = list(RouterPort.ROUTER_OPTIONS.keys())
model_name = "sentence-transformers/all-MiniLM-L6-v2"
self._model = SentenceTransformer(model_name)
self._route_embeddings = self._model.encode(sentence_keys)
def find_route(self, query: str) -> Route:
query_embedding = self._model.encode([query])[0]
similarities = [
EmbeddingRouterAdapter.similarity(query_embedding, emb)
for emb in self._route_embeddings
]
best_idx = np.argmax(similarities)
route_keys = list(RouterPort.ROUTER_OPTIONS.keys())
best_route = route_keys[best_idx]
return RouterPort.ROUTER_OPTIONS[best_route]
Loading a sentence transformer model takes a few seconds. This cost is paid once at startup and is negligible afterward — query-time encoding of a short string is fast. However, in some environments the model may not be available: the host may lack the memory, the dependency may not be installed, or the model download may time out. This motivates a fallback strategy.
LLM-Based Routing
A third option requires no local ML model at all: just ask an LLM. The system prompt lists the available routes; the model reads the user’s query and replies with exactly one route name. This handles completely novel phrasing and implicit intent better than either of the above approaches, and the only dependency is an API client. The tradeoff is latency — each routing decision requires a network round-trip — and per-call cost, which makes it unsuitable at high QPS but perfectly reasonable for moderate traffic.
class LLMRouterAdapter(RouterPort):
_SYSTEM_PROMPT = (
"You are a query router. Given a user message, reply with exactly one of "
"the following route names and nothing else: "
+ ", ".join(r.value for r in Route)
)
def __init__(self, client: anthropic.Anthropic) -> None:
self._client = client
def find_route(self, query: str) -> Route:
response = self._client.messages.create(
model="claude-haiku-4-5-20251001",
max_tokens=20,
system=self._SYSTEM_PROMPT,
messages=[{"role": "user", "content": query}],
)
route_name = response.content[0].text.strip()
return Route(route_name)
Using a small, fast model like Haiku keeps latency and cost low while still benefiting from
full language understanding. The max_tokens=20 cap enforces the single-token
response contract and prevents the model from elaborating.
Composition and Fallback
CompositionRouterAdapter attempts to initialize the embedding adapter with a
timeout. If it succeeds, all subsequent queries are routed through embeddings. If it fails for
any reason, it silently falls back to the Jaccard adapter. Either way, the caller gets the same
RouterPort interface and is unaware of which implementation is running.
class CompositionRouterAdapter(RouterPort):
def __init__(self) -> None:
executor = ThreadPoolExecutor(max_workers=1)
future: Future[EmbeddingRouterAdapter] = executor.submit(EmbeddingRouterAdapter)
try:
self._adapter: RouterPort = future.result(timeout=60)
except Exception:
self._adapter = JaccardRouterAdapter()
finally:
executor.shutdown(wait=False)
def find_route(self, query: str) -> Route:
return self._adapter.find_route(query)
Tradeoffs
Jaccard over n-grams is fast, requires no ML dependencies, and is robust to typos. Its
weakness is vocabulary: it can only match what it can see at the surface level, and novel
phrasings with no textual overlap will score poorly. It is also sensitive to the quality of the
descriptions in ROUTER_OPTIONS — a sparse or poorly worded description set
will produce unreliable results.
Embedding-based routing handles paraphrase and semantic drift much better, at the cost of a model loading step and a heavier dependency. For most production deployments where the environment is controlled, this is the right default. The composition pattern lets you ship the embedding router with confidence while keeping the Jaccard adapter as insurance against unexpected environments or model failures.
LLM-based routing offers the strongest language understanding with no local ML dependencies, at the cost of per-call latency and API spend. It works well when routing decisions are infrequent or when query complexity genuinely requires language model reasoning to resolve ambiguity. It can also slot into the composition chain: try embeddings first, fall back to the LLM for low-confidence cases, and use Jaccard as the last resort.
A few other considerations:
- Route description quality matters. Both approaches compare queries against
the strings in
ROUTER_OPTIONS. Investing in a diverse, representative set of descriptions — covering different phrasings, levels of formality, and common misspellings — improves accuracy for both adapters. - Confidence thresholds. Neither adapter currently rejects low-confidence matches. Adding a minimum score threshold and surfacing a “no route found” result is straightforward and can prevent garbage-in-garbage-out routing.
- Scaling to many routes. With a small number of routes the linear scan over all descriptions is fine. With hundreds of routes, approximate nearest-neighbor search over the embedding vectors (e.g., using FAISS) would be appropriate. In this case, we should store the route descriptions in an actual vector database.